(cherry picked from commit 8f43fb5389)
Rather than passing a bunch of arguments to be filled in with the
content of the ceph_auth_handshake buffer now returned by the
get_authorizer method, just use the returned information in the
caller, and drop the unnecessary arguments.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit a3530df33e)
Have the get_authorizer auth_client method return a ceph_auth
pointer rather than an integer, pointer-encoding any returned
error value. This is to pave the way for making use of the
returned value in an upcoming patch.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit a255651d4c)
In the create_authorizer method for both the mds and osd clients,
the auth_client->ops pointer is blindly dereferenced. There is no
obvious guarantee that this pointer has been assigned. And
furthermore, even if the ops pointer is non-null there is definitely
no guarantee that the create_authorizer or destroy_authorizer
methods are defined.
Add checks in both routines to make sure they are defined (non-null)
before use. Add similar checks in a few other spots in these files
while we're at it.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 74f1869f76)
Make use of the new ceph_auth_handshake structure in order to reduce
the number of arguments passed to the create_authorizor method in
ceph_auth_client_ops. Use a local variable of that type as a
shorthand in the get_authorizer method definitions.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 6c4a19158b)
The definitions for the ceph_mds_session and ceph_osd both contain
five fields related only to "authorizers." Encapsulate those fields
into their own struct type, allowing for better isolation in some
upcoming patches.
Fix the #includes in "linux/ceph/osd_client.h" to lay out their more
complete canonical path.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit ed96af6460)
In prepare_connect_authorizer(), a connection's get_authorizer
method is called but ignores its return value. This function can
return an error, so check for it and return it if that ever occurs.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit b1c6b9803f)
Change prepare_connect_authorizer() so it returns without dropping
the connection mutex if the connection has no get_authorizer method.
Use the symbolic CEPH_AUTH_UNKNOWN instead of 0 when assigning
authorization protocols.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 5a0f8fdd8a)
prepare_write_connect() can return an error, but only one of its
callers checks for it. All the rest are in functions that already
return errors, so it should be fine to return the error if one
gets returned.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit e10c758e40)
prepare_write_connect() prepares a connect message, then sets
WRITE_PENDING on the connection. Then *after* this, it calls
prepare_connect_authorizer(), which updates the content of the
connection buffer already queued for sending. It's also possible it
will result in prepare_write_connect() returning -EAGAIN despite the
WRITE_PENDING big getting set.
Fix this by preparing the connect authorizer first, setting the
WRITE_PENDING bit only after that is done.
Partially addresses http://tracker.newdream.net/issues/2424
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit e825a66df9)
In all cases, the value passed as the msgr argument to
prepare_write_connect() is just con->msgr. Just get the msgr
value from the ceph connection and drop the unneeded argument.
The only msgr passed to prepare_write_banner() is also therefore
just the one from con->msgr, so change that function to drop the
msgr argument as well.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 41b90c0085)
prepare_write_connect() has an argument indicating whether a banner
should be sent out before sending out a connection message. It's
only ever set in one of its callers, so move the code that arranges
to send the banner into that caller and drop the "include_banner"
argument from prepare_write_connect().
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 84fb3adf64)
Reset a connection's kvec fields in the caller rather than in
prepare_write_connect(). This ends up repeating a few lines of
code but it's improving the separation between distinct operations
on the connection, which we can take advantage of later.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit d329156f16)
Move the kvec reset for a connection out of prepare_write_banner and
into its only caller.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit fd51653f78)
Make the second argument to read_partial() be the ending input byte
position rather than the beginning offset it now represents. This
amounts to moving the addition "to + size" into the caller.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit e6cee71fac)
read_partial() always increases whatever "to" value is supplied by
adding the requested size to it, and that's the only thing it does
with that pointed-to value.
Do that pointer advance in the caller (and then only when the
updated value will be subsequently used), and change the "to"
parameter to be an in-only and non-pointer value.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 57dac9d162)
There are two blocks of code in read_partial_message()--those that
read the header and footer of the message--that can be replaced by a
call to read_partial(). Do that.
Signed-off-by: Alex Elder <elder@inktank.com>
Reviewed-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 065a68f916)
From Al Viro <viro@zeniv.linux.org.uk>
Al Viro noticed that we were using a non-cpu-encoded value in
a switch statement in osd_req_encode_op(). The result would
clearly not work correctly on a big-endian machine.
Signed-off-by: Alex Elder <elder@dreamhost.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit f671d4cd9b)
Fix the node weight lookup for tree buckets by using a correct accessor.
Reflects ceph.git commit d287ade5bcbdca82a3aef145b92924cf1e856733.
Reviewed-by: Alex Elder <elder@inktank.com>
Signed-off-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit a1f4895be8)
If we get a map that doesn't make sense, error out or ignore the badness
instead of BUGging out. This reflects the ceph.git commits
9895f0bff7dc68e9b49b572613d242315fb11b6c and
8ded26472058d5205803f244c2f33cb6cb10de79.
Reviewed-by: Alex Elder <elder@inktank.com>
Signed-off-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit c90f95ed46)
This small adjustment reflects a change that was made in ceph.git commit
af6a9f30696c900a2a8bd7ae24e8ed15fb4964bb, about 6 months ago. An N-1
search is not exhaustive. Fixed ceph.git bug #1594.
Reviewed-by: Alex Elder <elder@inktank.com>
Signed-off-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 8b12d47b80)
Move various types from int -> __u32 (or similar), and add const as
appropriate.
This reflects changes that have been present in the userland implementation
for some time.
Reviewed-by: Alex Elder <elder@inktank.com>
Signed-off-by: Sage Weil <sage@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 361d94a338 upstream.
Calls into reiserfs journalling code and reiserfs_get_block() need to
be protected with write lock. We remove write lock around calls to high
level quota code in the next patch so these paths would suddently become
unprotected.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 7af1168693 upstream.
Calls into highlevel quota code cannot happen under the write lock. These
calls take dqio_mutex which ranks above write lock. So drop write lock
before calling back into quota code.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b9e06ef2e8 upstream.
In reiserfs_quota_on() we do quite some work - for example unpacking
tail of a quota file. Thus we have to hold write lock until a moment
we call back into the quota code.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3bb3e1fc47 upstream.
When remounting reiserfs dquot_suspend() or dquot_resume() can be called.
These functions take dqonoff_mutex which ranks above write lock so we have
to drop it before calling into quota code.
Signed-off-by: Jan Kara <jack@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 399f11c3d8 upstream.
Currently, we will schedule session recovery and then return to the
caller of nfs4_handle_exception. This works for most cases, but causes
a hang on the following test case:
Client Server
------ ------
Open file over NFS v4.1
Write to file
Expire client
Try to lock file
The server will return NFS4ERR_BADSESSION, prompting the client to
schedule recovery. However, the client will continue placing lock
attempts and the open recovery never seems to be scheduled. The
simplest solution is to wait for session recovery to run before retrying
the lock.
Signed-off-by: Bryan Schumaker <bjschuma@netapp.com>
Signed-off-by: Trond Myklebust <Trond.Myklebust@netapp.com>
[bwh: Backported to 3.2: adjust context]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit a9193983f4 upstream.
The overlay on the i830M has a peculiar failure mode: It works the
first time around after boot-up, but consistenly hangs the second time
it's used.
Chris Wilson has dug out a nice errata:
"1.5.12 Clock Gating Disable for Display Register
Address Offset: 06200h–06203h
"Bit 3
Ovrunit Clock Gating Disable.
0 = Clock gating controlled by unit enabling logic
1 = Disable clock gating function
DevALM Errata ALM049: Overlay Clock Gating Must be Disabled: Overlay
& L2 Cache clock gating must be disabled in order to prevent device
hangs when turning off overlay.SW must turn off Ovrunit clock gating
(6200h) and L2 Cache clock gating (C8h)."
Now I've nowhere found that 0xc8 register and hence couldn't apply the
l2 cache workaround. But I've remembered that part of the magic that
the OVERLAY_ON/OFF commands are supposed to do is to rearrange cache
allocations so that the overlay scaler has some scratch space.
And while pondering how that could explain the hang the 2nd time we
enable the overlay, I've remembered that the old ums overlay code did
_not_ issue the OVERLAY_OFF cmd.
And indeed, disabling the OFF cmd results in the overlay working
flawlessly, so I guess we can workaround the lack of the above
workaround by simply never disabling the overlay engine once it's
enabled.
Note that we have the first part of the above w/a already implemented
in i830_init_clock_gating - leave that as-is to avoid surprises.
v2: Add a comment in the code.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=47827
Tested-by: Rhys <rhyspuk@gmail.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- Adjust context
- s/intel_ring_emit(ring, /OUT_RING(/]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit fa968ee215 upstream.
If user space is running in primary mode it can switch to secondary
or access register mode, this is used e.g. in the clock_gettime code
of the vdso. If a signal is delivered to the user space process while
it has been running in access register mode the signal handler is
executed in access register mode as well which will result in a crash
most of the time.
Set the address space control bits in the PSW to the default for the
execution of the signal handler and make sure that the previous
address space control is restored on signal return. Take care
that user space can not switch to the kernel address space by
modifying the registers in the signal frame.
Signed-off-by: Martin Schwidefsky <schwidefsky@de.ibm.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d663d181b9 upstream.
Re-enable interrupts if it is not our interrupt
Signed-off-by: Mirko Lindner <mlindner@marvell.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Cc: Jonathan Nieder <jrnieder@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 5f5b331d5c upstream.
The issue occurs when eCryptfs is mounted with a cipher supported by
the crypto subsystem but not by eCryptfs. The mount succeeds and an
error does not occur until a write. This change checks for eCryptfs
cipher support at mount time.
Resolves Launchpad issue #338914, reported by Tyler Hicks in 03/2009.
https://bugs.launchpad.net/ecryptfs/+bug/338914
Signed-off-by: Tim Sally <tsally@atomicpeace.com>
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Cc: Herton Ronaldo Krzesinski <herton.krzesinski@canonical.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 069ddcda37 upstream.
When the eCryptfs mount options do not include '-o acl', but the lower
filesystem's mount options do include 'acl', the MS_POSIXACL flag is not
flipped on in the eCryptfs super block flags. This flag is what the VFS
checks in do_last() when deciding if the current umask should be applied
to a newly created inode's mode or not. When a default POSIX ACL mask is
set on a directory, the current umask is incorrectly applied to new
inodes created in the directory. This patch ignores the MS_POSIXACL flag
passed into ecryptfs_mount() and sets the flag on the eCryptfs super
block depending on the flag's presence on the lower super block.
Additionally, it is incorrect to allow a writeable eCryptfs mount on top
of a read-only lower mount. This missing check did not allow writes to
the read-only lower mount because permissions checks are still performed
on the lower filesystem's objects but it is best to simply not allow a
rw mount on top of ro mount. However, a ro eCryptfs mount on top of a rw
mount is valid and still allowed.
https://launchpad.net/bugs/1009207
Signed-off-by: Tyler Hicks <tyhicks@canonical.com>
Reported-by: Stefan Beller <stefanbeller@googlemail.com>
Cc: John Johansen <john.johansen@canonical.com>
Cc: Herton Ronaldo Krzesinski <herton.krzesinski@canonical.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0658a3366d upstream.
The use of kfree(serial) in error cases of usb_serial_probe
was invalid - usb_serial structure allocated in create_serial()
gets reference of usb_device that needs to be put, so we need
to use usb_serial_put() instead of simple kfree().
Signed-off-by: Jan Safrata <jan.nikitenko@gmail.com>
Acked-by: Johan Hovold <jhovold@gmail.com>
Cc: Richard Retanubun <richardretanubun@ruggedcom.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 38fe36a248 upstream.
ICMP tuples have id in src and type/code in dst.
So comparing src.u.all with dst.u.all will always fail here
and ip_xfrm_me_harder() is called for every ICMP packet,
even if there was no NAT.
Signed-off-by: Ulrich Weber <ulrich.weber@sophos.com>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 64f509ce71 upstream.
Clients should not send such packets. By accepting them, we open
up a hole by wich ephemeral ports can be discovered in an off-path
attack.
See: "Reflection scan: an Off-Path Attack on TCP" by Jan Wrobel,
http://arxiv.org/abs/1201.2074
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 4a70bbfaef upstream.
We spare nothing by not validating the sequence number of dataless
ACK packets and enabling it makes harder off-path attacks.
See: "Reflection scan: an Off-Path Attack on TCP" by Jan Wrobel,
http://arxiv.org/abs/1201.2074
Signed-off-by: Jozsef Kadlecsik <kadlec@blackhole.kfki.hu>
Signed-off-by: Pablo Neira Ayuso <pablo@netfilter.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0481776b7a upstream.
RTL_GIGA_MAC_VER_35 includes no multicast hardware filter.
Signed-off-by: Nathan Walp <faceprint@faceprint.com>
Suggested-by: Hayes Wang <hayeswang@realtek.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b00e69dee4 upstream.
This regression was spotted between Debian squeeze and Debian wheezy
kernels (respectively based on 2.6.32 and 3.2). More info about
Wake-on-LAN issues with Realtek's 816x chipsets can be found in the
following thread: http://marc.info/?t=132079219400004
Probable regression from d4ed95d796e5126bba51466dc07e287cebc8bd19;
more chipsets are likely affected.
Tested on top of a 3.2.23 kernel.
Reported-by: Florent Fourcot <florent.fourcot@enst-bretagne.fr>
Tested-by: Florent Fourcot <florent.fourcot@enst-bretagne.fr>
Hinted-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: Cyril Brulebois <kibi@debian.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit aee77e4acc upstream.
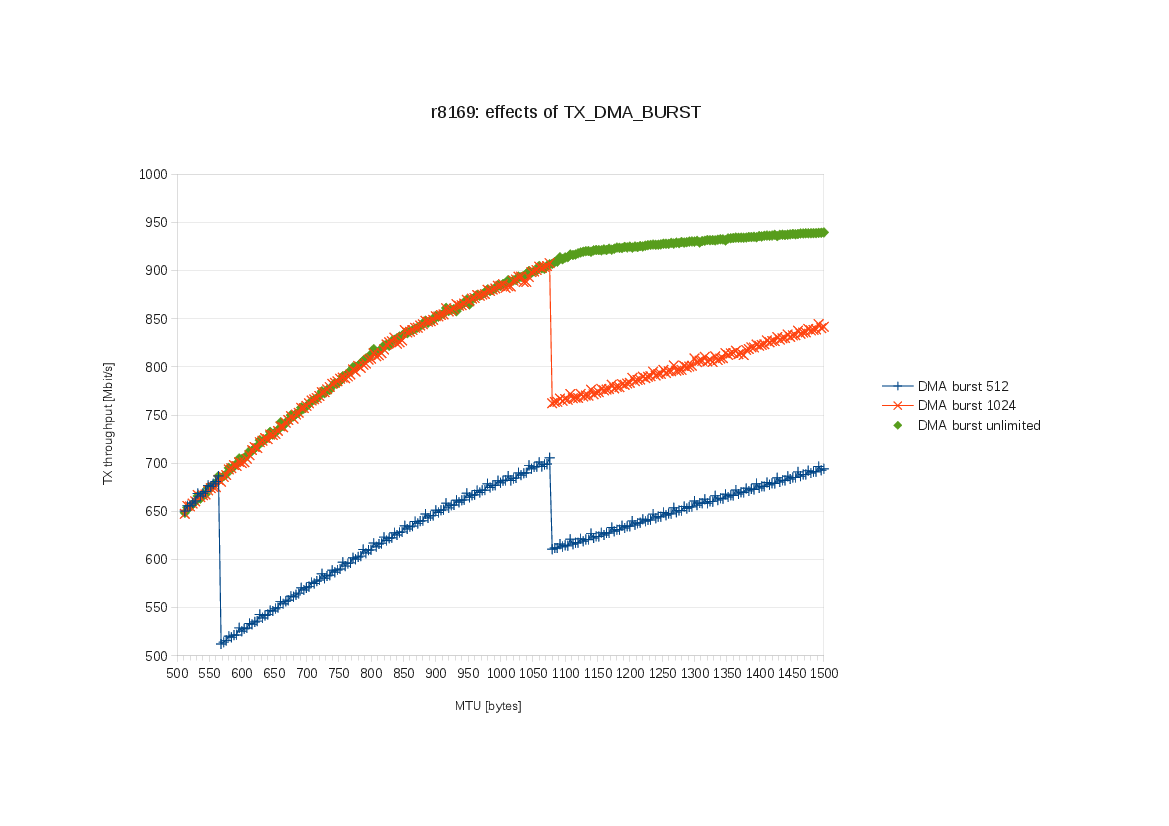
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0f3c42f522 upstream.
Under a particular load on one machine, I have hit shmem_evict_inode()'s
BUG_ON(inode->i_blocks), enough times to narrow it down to a particular
race between swapout and eviction.
It comes from the "if (freed > 0)" asymmetry in shmem_recalc_inode(),
and the lack of coherent locking between mapping's nrpages and shmem's
swapped count. There's a window in shmem_writepage(), between lowering
nrpages in shmem_delete_from_page_cache() and then raising swapped
count, when the freed count appears to be +1 when it should be 0, and
then the asymmetry stops it from being corrected with -1 before hitting
the BUG.
One answer is coherent locking: using tree_lock throughout, without
info->lock; reasonable, but the raw_spin_lock in percpu_counter_add() on
used_blocks makes that messier than expected. Another answer may be a
further effort to eliminate the weird shmem_recalc_inode() altogether,
but previous attempts at that failed.
So far undecided, but for now change the BUG_ON to WARN_ON: in usual
circumstances it remains a useful consistency check.
Signed-off-by: Hugh Dickins <hughd@google.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit baefa31db2 ]
In commit c445477d74 which adds aRFS to the kernel, the CPU
selected for RFS is not set correctly when CPU is changing.
This is causing OOO packets and probably other issues.
Signed-off-by: Tom Herbert <therbert@google.com>
Acked-by: Eric Dumazet <edumazet@google.com>
Acked-by: Ben Hutchings <bhutchings@solarflare.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit a652208e0b ]
Check (ha->addr == dev->dev_addr) is always true because dev_addr_init()
sets this. Correct the check to behave properly on addr removal.
Signed-off-by: Jiri Pirko <jiri@resnulli.us>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit d4596bad2a ]
Cc: Stephen Hemminger <shemminger@vyatta.com>
Signed-off-by: Hannes Frederic Sowa <hannes@stressinduktion.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 0c9f79be29 ]
(1<<optname) is undefined behavior in C with a negative optname or
optname larger than 31. In those cases the result of the shift is
not necessarily zero (e.g., on x86).
This patch simplifies the code with a switch statement on optname.
It also allows the compiler to generate better code (e.g., using a
64-bit mask).
Signed-off-by: Xi Wang <xi.wang@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 34fa78b59c upstream.
The sigaddset/sigdelset/sigismember functions that are implemented with
bitfield insn cannot allow the sigset argument to be placed in a data
register since the sigset is wider than 32 bits. Remove the "d"
constraint from the asm statements.
The effect of the bug is that sending RT signals does not work, the signal
number is truncated modulo 32.
Signed-off-by: Andreas Schwab <schwab@linux-m68k.org>
Signed-off-by: Geert Uytterhoeven <geert@linux-m68k.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 43c771a196 upstream.
When in world roaming mode, allow 40 MHz to be used
on channels 12 and 13 so that an AP that is, e.g.,
using HT40+ on channel 9 (in the UK) can be used.
Reported-by: Eddie Chapman <eddie@ehuk.net>
Tested-by: Eddie Chapman <eddie@ehuk.net>
Acked-by: Luis R. Rodriguez <mcgrof@qca.qualcomm.com>
Signed-off-by: Johannes Berg <johannes.berg@intel.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 9a5a8f19b4 upstream.
oom_badness() takes a totalpages argument which says how many pages are
available and it uses it as a base for the score calculation. The value
is calculated by mem_cgroup_get_limit which considers both limit and
total_swap_pages (resp. memsw portion of it).
This is usually correct but since fe35004fbf ("mm: avoid swapping out
with swappiness==0") we do not swap when swappiness is 0 which means
that we cannot really use up all the totalpages pages. This in turn
confuses oom score calculation if the memcg limit is much smaller than
the available swap because the used memory (capped by the limit) is
negligible comparing to totalpages so the resulting score is too small
if adj!=0 (typically task with CAP_SYS_ADMIN or non zero oom_score_adj).
A wrong process might be selected as result.
The problem can be worked around by checking mem_cgroup_swappiness==0
and not considering swap at all in such a case.
Signed-off-by: Michal Hocko <mhocko@suse.cz>
Acked-by: David Rientjes <rientjes@google.com>
Acked-by: Johannes Weiner <hannes@cmpxchg.org>
Acked-by: KOSAKI Motohiro <kosaki.motohiro@jp.fujitsu.com>
Acked-by: KAMEZAWA Hiroyuki <kamezawa.hiroyu@jp.fujitsu.com>
Signed-off-by: Andrew Morton <akpm@linux-foundation.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ac207ed247 upstream.
The TTM page can be allocated from high memory. In such case it is
wrong to use the page_address(page) as the virtual address for the high memory
page.
bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=50241
Signed-off-by: Zhao Yakui <yakui.zhao@intel.com>
Reviewed-by: Thomas Hellstrom <thellstrom@vmware.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
{kind=link}