(cherry picked from commit f9f9a19044)
ceph_snap_context->snaps is an u64 array
Signed-off-by: Zheng Yan <zheng.z.yan@intel.com>
Reviewed-by: Alex Elder <elder@inktank.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 77dfe99fe3)
When a device was open at a snapshot, and snapshots were deleted or
added, data from the wrong snapshot could be read. Instead of
assuming the snap context is constant, store the actual snap id when
the device is initialized, and rely on the OSDs to signal an error
if we try reading from a snapshot that was deleted.
Signed-off-by: Josh Durgin <josh.durgin@dreamhost.com>
Reviewed-by: Alex Elder <elder@dreamhost.com>
Reviewed-by: Yehuda Sadeh <yehuda@hq.newdream.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit 403f24d3d5)
This is updated whenever a snapshot is added or deleted, and the
snapc pointer is changed with every refresh of the header.
Signed-off-by: Josh Durgin <josh.durgin@dreamhost.com>
Reviewed-by: Alex Elder <elder@dreamhost.com>
Reviewed-by: Yehuda Sadeh <yehuda@hq.newdream.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
(cherry picked from commit cd9d9f5df6)
A recent change made changes to the rbd_client_list be protected by
a spinlock. Unfortunately in rbd_put_client(), the lock is taken
before possibly dropping the last reference to an rbd_client, and on
the last reference that eventually calls flush_workqueue() which can
sleep.
The problem was flagged by a debug spinlock warning:
BUG: spinlock wrong CPU on CPU#3, rbd/27814
The solution is to move the spinlock acquisition and release inside
rbd_client_release(), which is the spot where it's really needed for
protecting the removal of the rbd_client from the client list.
Signed-off-by: Alex Elder <elder@dreamhost.com>
Reviewed-by: Sage Weil <sage@newdream.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit a9193983f4 upstream.
The overlay on the i830M has a peculiar failure mode: It works the
first time around after boot-up, but consistenly hangs the second time
it's used.
Chris Wilson has dug out a nice errata:
"1.5.12 Clock Gating Disable for Display Register
Address Offset: 06200h–06203h
"Bit 3
Ovrunit Clock Gating Disable.
0 = Clock gating controlled by unit enabling logic
1 = Disable clock gating function
DevALM Errata ALM049: Overlay Clock Gating Must be Disabled: Overlay
& L2 Cache clock gating must be disabled in order to prevent device
hangs when turning off overlay.SW must turn off Ovrunit clock gating
(6200h) and L2 Cache clock gating (C8h)."
Now I've nowhere found that 0xc8 register and hence couldn't apply the
l2 cache workaround. But I've remembered that part of the magic that
the OVERLAY_ON/OFF commands are supposed to do is to rearrange cache
allocations so that the overlay scaler has some scratch space.
And while pondering how that could explain the hang the 2nd time we
enable the overlay, I've remembered that the old ums overlay code did
_not_ issue the OVERLAY_OFF cmd.
And indeed, disabling the OFF cmd results in the overlay working
flawlessly, so I guess we can workaround the lack of the above
workaround by simply never disabling the overlay engine once it's
enabled.
Note that we have the first part of the above w/a already implemented
in i830_init_clock_gating - leave that as-is to avoid surprises.
v2: Add a comment in the code.
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=47827
Tested-by: Rhys <rhyspuk@gmail.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
[bwh: Backported to 3.2:
- Adjust context
- s/intel_ring_emit(ring, /OUT_RING(/]
Signed-off-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d663d181b9 upstream.
Re-enable interrupts if it is not our interrupt
Signed-off-by: Mirko Lindner <mlindner@marvell.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Cc: Jonathan Nieder <jrnieder@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0658a3366d upstream.
The use of kfree(serial) in error cases of usb_serial_probe
was invalid - usb_serial structure allocated in create_serial()
gets reference of usb_device that needs to be put, so we need
to use usb_serial_put() instead of simple kfree().
Signed-off-by: Jan Safrata <jan.nikitenko@gmail.com>
Acked-by: Johan Hovold <jhovold@gmail.com>
Cc: Richard Retanubun <richardretanubun@ruggedcom.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0481776b7a upstream.
RTL_GIGA_MAC_VER_35 includes no multicast hardware filter.
Signed-off-by: Nathan Walp <faceprint@faceprint.com>
Suggested-by: Hayes Wang <hayeswang@realtek.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b00e69dee4 upstream.
This regression was spotted between Debian squeeze and Debian wheezy
kernels (respectively based on 2.6.32 and 3.2). More info about
Wake-on-LAN issues with Realtek's 816x chipsets can be found in the
following thread: http://marc.info/?t=132079219400004
Probable regression from d4ed95d796e5126bba51466dc07e287cebc8bd19;
more chipsets are likely affected.
Tested on top of a 3.2.23 kernel.
Reported-by: Florent Fourcot <florent.fourcot@enst-bretagne.fr>
Tested-by: Florent Fourcot <florent.fourcot@enst-bretagne.fr>
Hinted-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: Cyril Brulebois <kibi@debian.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit aee77e4acc upstream.
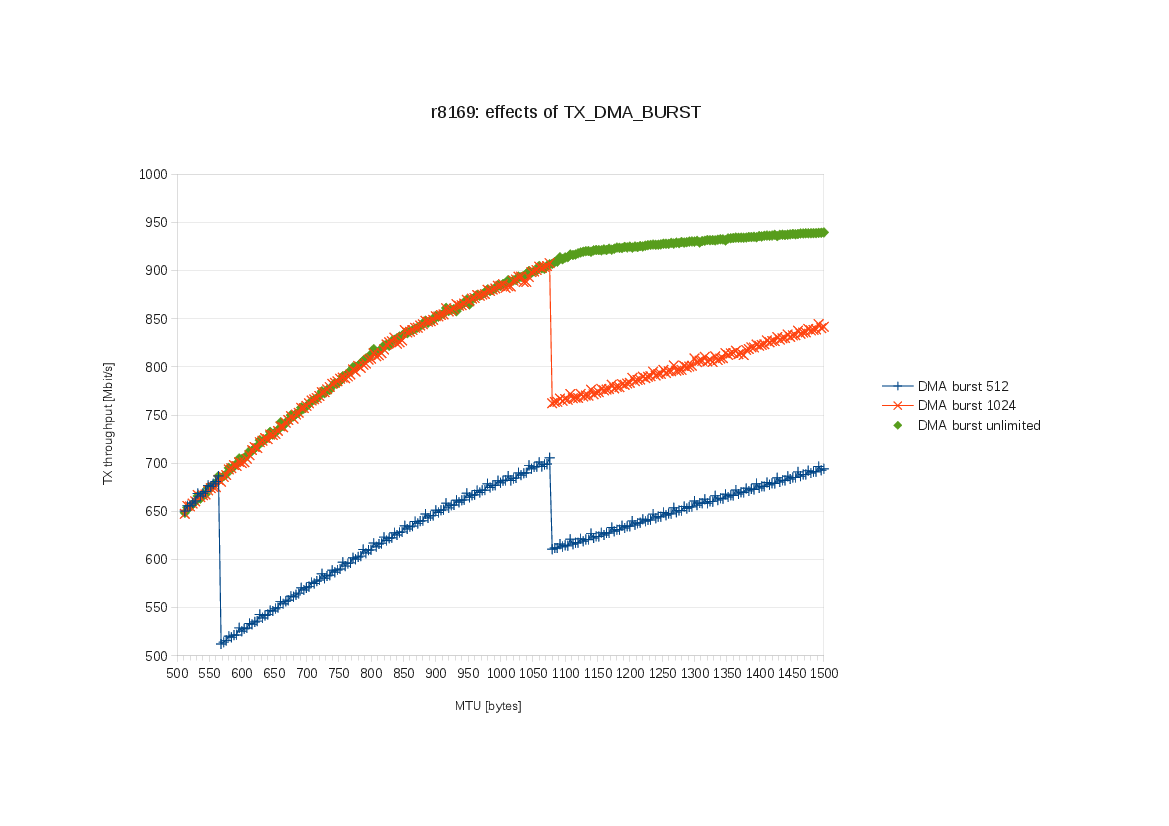
The r8169 driver currently limits the DMA burst for TX to 1024 bytes. I have
a box where this prevents the interface from using the gigabit line to its full
potential. This patch solves the problem by setting TX_DMA_BURST to unlimited.
The box has an ASRock B75M motherboard with on-board RTL8168evl/8111evl
(XID 0c900880). TSO is enabled.
I used netperf (TCP_STREAM test) to measure the dependency of TX throughput
on MTU. I did it for three different values of TX_DMA_BURST ('5'=512, '6'=1024,
'7'=unlimited). This chart shows the results:
http://michich.fedorapeople.org/r8169/r8169-effects-of-TX_DMA_BURST.png
Interesting points:
- With the current DMA burst limit (1024):
- at the default MTU=1500 I get only 842 Mbit/s.
- when going from small MTU, the performance rises monotonically with
increasing MTU only up to a peak at MTU=1076 (908 MBit/s). Then there's
a sudden drop to 762 MBit/s from which the throughput rises monotonically
again with further MTU increases.
- With a smaller DMA burst limit (512):
- there's a similar peak at MTU=1076 and another one at MTU=564.
- With unlimited DMA burst:
- at the default MTU=1500 I get nice 940 Mbit/s.
- the throughput rises monotonically with increasing MTU with no strange
peaks.
Notice that the peaks occur at MTU sizes that are multiples of the DMA burst
limit plus 52. Why 52? Because:
20 (IP header) + 20 (TCP header) + 12 (TCP options) = 52
The Realtek-provided r8168 driver (v8.032.00) uses unlimited TX DMA burst too,
except for CFG_METHOD_1 where the TX DMA burst is set to 512 bytes.
CFG_METHOD_1 appears to be the oldest MAC version of "RTL8168B/8111B",
i.e. RTL_GIGA_MAC_VER_11 in r8169. Not sure if this MAC version really needs
the smaller burst limit, or if any other versions have similar requirements.
Signed-off-by: Michal Schmidt <mschmidt@redhat.com>
Acked-by: Francois Romieu <romieu@fr.zoreil.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ac207ed247 upstream.
The TTM page can be allocated from high memory. In such case it is
wrong to use the page_address(page) as the virtual address for the high memory
page.
bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=50241
Signed-off-by: Zhao Yakui <yakui.zhao@intel.com>
Reviewed-by: Thomas Hellstrom <thellstrom@vmware.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit fcb21645f1 upstream.
The Dell 5800 appears to be a simple rebrand of the Novatel E362.
Signed-off-by: Dan Williams <dcbw@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d38e0e3fed upstream.
Commit 6bd4a5d96c changed the
ANDROID_ALARM_GET_TIME ioctls from IOW to IOR. While technically
correct, the _IOC_DIR bits are ignored by alarm_ioctl, so the
commit breaks a userspace ABI used by all existing Android devices
for a purely cosmetic reason. Revert it.
Cc: Dae S. Kim <dae@velatum.com>
Signed-off-by: Colin Cross <ccross@android.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Fix warning about unused variable introduced by commit e681b66f2e
("USB: mos7840: remove invalid disconnect handling") upstream.
A subsequent fix which removed the disconnect function got rid of the
warning but that one was only backported to v3.6.
Reported-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Johan Hovold <jhovold@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit b6e0e543f7 upstream.
Like in the case of native hdmi, which is fixed already in
commit adf00b26d1
Author: Paulo Zanoni <paulo.r.zanoni@intel.com>
Date: Tue Sep 25 13:23:34 2012 -0300
drm/i915: make sure we write all the DIP data bytes
we need to clear the entire sdvo buffer to avoid upsetting the
display.
Since infoframe buffer writing is now a bit more elaborate, extract it
into it's own function. This will be useful if we ever get around to
properly update the ELD for sdvo. Also #define proper names for the
two buffer indexes with fixed usage.
v2: Cite the right commit above, spotted by Paulo Zanoni.
v3: I'm too stupid to paste the right commit.
v4: Ben Hutchings noticed that I've failed to handle an underflow in
my loop logic, breaking it for i >= length + 8. Since I've just lost C
programmer license, use his solution. Also, make the frustrated 0-base
buffer size a notch more clear.
Reported-and-tested-by: Jürg Billeter <j@bitron.ch>
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Cc: Paulo Zanoni <przanoni@gmail.com>
Cc: Ben Hutchings <ben@decadent.org.uk>
Reviewed-by: Rodrigo Vivi <rodrigo.vivi@gmail.com>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 81014b9d0b upstream.
At least the worst offenders:
- SDVO specifies that the encoder should compute the ecc. Testing also
shows that we must not send the ecc field, so copy the dip_infoframe
struct to a temporay place and avoid the ecc field. This way the avi
infoframe is exactly 17 bytes long, which agrees with what the spec
mandates as a minimal storage capacity (with the ecc field it would
be 18 bytes).
- Only 17 when sending the avi infoframe. The SDVO spec explicitly
says that sending more data than what the device announces results
in undefined behaviour.
- Add __attribute__((packed)) to the avi and spd infoframes, for
otherwise they're wrongly aligned. Noticed because the avi infoframe
ended up being 18 bytes large instead of 17. We haven't noticed this
yet because we don't use the uint16_t fields yet (which are the only
ones that would be wrongly aligned).
This regression has been introduce by
3c17fe4b8f is the first bad commit
commit 3c17fe4b8f
Author: David Härdeman <david@hardeman.nu>
Date: Fri Sep 24 21:44:32 2010 +0200
i915: enable AVI infoframe for intel_hdmi.c [v4]
Patch tested on my g33 with a sdvo hdmi adaptor.
Bugzilla: https://bugzilla.kernel.org/show_bug.cgi?id=25732
Tested-by: Peter Ross <pross@xvid.org> (G35 SDVO-HDMI)
Reviewed-by: Eugeni Dodonov <eugeni.dodonov@intel.com>
Signed-Off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Cc: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit f418b88aad upstream.
This register is needed for streamout to work properly.
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Reviewed-by: Michel Dänzer <michel.daenzer@amd.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 860fe2f05f upstream.
These regs were being wronly rejected leading to rendering
issues.
fixes:
https://bugs.freedesktop.org/show_bug.cgi?id=56876
Signed-off-by: Alex Deucher <alexander.deucher@amd.com>
Reviewed-by: Michel Dänzer <michel.daenzer@amd.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 95e8f6a219 upstream.
The device would not reset properly when resuming from hibernation.
Signed-off-by: Thomas Hellstrom <thellstrom@vmware.com>
Reviewed-by: Brian Paul <brianp@vmware.com>
Reviewed-by: Dmitry Torokhov <dtor@vmware.com>
Cc: linux-graphics-maintainer@vmware.com
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 14efd95720 upstream.
Commit 473b095a72 ("mmc: sdhci: fix incorrect command used in tuning")
introduced a NULL dereference at resume-time if an SD 3.0 host controller
raises the SDHCI_NEEDS_TUNING flag while no card is inserted. Seen on an
OLPC XO-4 with sdhci-pxav3, but presumably affects other controllers too.
Signed-off-by: Chris Ball <cjb@laptop.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 57c10b61c8 ]
Based on commit b27393aecf
Calling mdiobus_free without calling mdiobus_unregister causes
BUG_ON(). This patch fixes the issue.
The semantic patch that found this issue(http://coccinelle.lip6.fr/):
// <smpl>
@@
expression E;
@@
... when != mdiobus_unregister(E);
+ mdiobus_unregister(E);
mdiobus_free(E);
// </smpl>
Signed-off-by: Peter Senna Tschudin <peter.senna@gmail.com>
Tested-by: Roland Stigge <stigge@antcom.de>
Tested-by: Alexandre Pereira da Silva <aletes.xgr@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
[ Upstream commit 39707c2a3b ]
Driver anchors the tx urbs and defers the urb submission if
a transmit request comes when the interface is suspended.
Anchoring urb increments the urb reference count. These
deferred urbs are later accessed by calling usb_get_from_anchor()
for submission during interface resume. usb_get_from_anchor()
unanchors the urb but urb reference count remains same.
This causes the urb reference count to remain non-zero
after usb_free_urb() gets called and urb never gets freed.
Hence call usb_put_urb() after anchoring the urb to properly
balance the reference count for these deferred urbs. Also,
unanchor these deferred urbs during disconnect, to free them
up.
Signed-off-by: Hemant Kumar <hemantk@codeaurora.org>
Acked-by: Oliver Neukum <oneukum@suse.de>
Signed-off-by: David S. Miller <davem@davemloft.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3300fb4f88 upstream.
Don't assume bank 0 is selected at device probe time. This may not be
the case. Force bank selection at first register access to guarantee
that we read the right registers upon driver loading.
Signed-off-by: Jean Delvare <khali@linux-fr.org>
Reviewed-by: Guenter Roeck <linux@roeck-us.net>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0f1cb1bd94 upstream.
If drm_setup (called at first open) fails, the whole
open call has failed, so we should not keep the
open_count incremented.
Signed-off-by: Ilija Hadzic <ihadzic@research.bell-labs.com>
Reviewed-by: Thomas Hellstrom <thellstrom@vmware.com>
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3916e1d71b upstream.
When buffer sharing with the i915 and using a 1680x1050 monitor,
the i915 gives is a 6912 buffer for the 6720 width, the code doesn't
render this properly as it uses one value to set the base address for
reading from the vmap and for where to start on the device.
This fixes it by calculating the values correctly for the device and
for the pixmap. No idea how I haven't seen this before now.
Signed-off-by: Dave Airlie <airlied@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ab74b3d62f upstream.
This patch changes core_tmr_abort_task() to use spin_lock -> spin_unlock
around se_cmd->t_state_lock while spin_lock_irqsave is held via
se_sess->sess_cmd_lock.
Signed-off-by: Steve Hodgson <steve@purestorage.com>
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d5627acba9 upstream.
The sleeping code in iscsi_target_tx_thread() is susceptible to the classic
missed wakeup race:
- TX thread finishes handle_immediate_queue() and handle_response_queue(),
thinks both queues are empty.
- Another thread adds a queue entry and does wake_up_process(), which does
nothing because the TX thread is still awake.
- TX thread does schedule_timeout() and sleeps forever.
In practice this can kill an iSCSI connection if for example an initiator
does single-threaded writes and the target misses the wakeup window when
queueing an R2T; in this case the connection will be stuck until the
initiator loses patience and does some task management operation (or kills
the connection entirely).
Fix this by converting to wait_event_interruptible(), which does not
suffer from this sort of race.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Cc: Andy Grover <agrover@redhat.com>
Cc: Hannes Reinecke <hare@suse.de>
Cc: Christoph Hellwig <hch@lst.de>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3e03989b58 upstream.
The expression (max_sectors * block_size) might overflow a u32
(indeed, since iblock sets max_hw_sectors to UINT_MAX, it is
guaranteed to overflow and end up with a much-too-small result in many
common cases). Fix this by doing an equivalent calculation that
doesn't require multiplication.
While we're touching this code, avoid splitting a printk format across
two lines and use pr_info(...) instead of printk(KERN_INFO ...).
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 0d0f9dfb31 upstream.
If the call to core_dev_release_virtual_lun0() fails, then nothing
sets ret to anything other than 0, so even though everything is
torn down and freed, target_core_init_configfs() will seem to succeed
and the module will be loaded. Fix this by passing the return value
on up the chain.
Signed-off-by: Roland Dreier <roland@purestorage.com>
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit bf7e1abe43 upstream.
Some hardware has correct (!= 0xff) value of tssi_bounds[4] in the
EEPROM, but step is equal to 0xff. This results on ridiculous delta
calculations and completely broke TX power settings.
Reported-and-tested-by: Pavel Lucik <pavel.lucik@gmail.com>
Signed-off-by: Stanislaw Gruszka <sgruszka@redhat.com>
Acked-by: Ivo van Doorn <IvDoorn@gmail.com>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 6fe7cc71bb upstream.
The ath9k xmit functions for AMPDUs can send frames as non-aggregate in case
only one frame is currently available. The client will then answer using a
normal Ack instead of a BlockAck. This acknowledgement has no TID stored and
therefore the hardware is not able to provide us the corresponding TID.
The TID set by the hardware in the tx status descriptor has to be seen as
undefined and not as a valid TID value for normal acknowledgements. Doing
otherwise results in a massive amount of retransmissions and stalls of
connections.
Users may experience low bandwidth and complete connection stalls in
environments with transfers using multiple TIDs.
This regression was introduced in b11b160def
("ath9k: validate the TID in the tx status information").
Signed-off-by: Sven Eckelmann <sven@narfation.org>
Signed-off-by: Simon Wunderlich <siwu@hrz.tu-chemnitz.de>
Acked-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 8c6e30936a upstream.
bf->bf_next is only while buffers are chained as part of an A-MPDU
in the tx queue. When a tid queue is flushed (e.g. on tearing down
an aggregation session), frames can be enqueued again as normal
transmission, without bf_next being cleared. This can lead to the
old pointer being dereferenced again later.
This patch might fix crashes and "Failed to stop TX DMA!" messages.
Signed-off-by: Felix Fietkau <nbd@openwrt.org>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 32ed1911fc upstream.
The tsc40 driver announces it supports the pressure event, but will never
send one. The announcement will cause tslib to wait for such events and
sending all touch events with a pressure of 0. Removing the announcement
will make tslib fall back to emulating the pressure on touch events so
everything works as expected.
Signed-off-by: Rolf Eike Beer <eike-kernel@sf-tec.de>
Signed-off-by: Dmitry Torokhov <dmitry.torokhov@gmail.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit a67baeb773 upstream.
map->kmap_ops allocated in gntdev_alloc_map() wasn't freed by
gntdev_put_map().
Add a gntdev_free_map() helper function to free everything allocated
by gntdev_alloc_map().
Signed-off-by: David Vrabel <david.vrabel@citrix.com>
Signed-off-by: Konrad Rzeszutek Wilk <konrad.wilk@oracle.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
This is to prevent nouveau from taking over the console on headless boards
such as Tesla.
Backport of upstream commit: e412e95a26
Signed-off-by: Ben Skeggs <bskeggs@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
Backport of fixes from upstream commit:
9430738d80
Signed-off-by: Ben Skeggs <bskeggs@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 3ccc60f9d8 upstream.
Microsoft Digital Media Keyboard 3000 has two interfaces, and the
second one has a report descriptor with a bug. The second collection
says:
05 01 -- global; usage page -- 01 -- Generic Desktop Controls
09 80 -- local; usage -- 80 -- System Control
a1 01 -- main; collection -- 01 -- application
85 03 -- global; report ID -- 03
19 00 -- local; Usage Minimum -- 00
29 ff -- local; Usage Maximum -- ff
15 00 -- global; Logical Minimum -- 0
26 ff 00 -- global; Logical Maximum -- ff
81 00 -- main; input
c0 -- main; End Collection
I.e. it makes us think that there are all kinds of usages of system
control. That the keyboard is a not only a keyboard, but also a
joystick, mouse, gamepad, keypad, etc. The same as for the Wireless
Desktop Receiver, this should be Physical Min/Max. So fix that
appropriately.
References: https://bugzilla.novell.com/show_bug.cgi?id=776834
Signed-off-by: Jiri Slaby <jslaby@suse.cz>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit e13d5fef88 upstream.
Fabric drivers currently expect to internally release se_cmd in the event
of a TMR failure during target_submit_tmr(), which means the immediate call
to transport_generic_free_cmd() after TFO->queue_tm_rsp() from within
target_complete_tmr_failure() workqueue context is wrong.
This is done as some fabrics expect TMR operations to be acknowledged
before releasing the descriptor, so the assumption that core is releasing
se_cmd associated TMR memory is incorrect. This fixes a OOPs where
transport_generic_free_cmd() was being called more than once.
This bug was originally observed with tcm_qla2xxx fabric ports.
Signed-off-by: Nicholas Bellinger <nab@linux-iscsi.org>
Cc: Christoph Hellwig <hch@lst.de>
Cc: Roland Dreier <roland@purestorage.com>
Cc: Andy Grover <agrover@redhat.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit f89ff6441d upstream.
When b43 fails to find firmware when loaded, a subsequent unload will
oops due to calling ieee80211_unregister_hw() when the corresponding
register call was never made.
Commit 2d838bb608 fixed the same problem
for b43legacy.
Signed-off-by: Larry Finger <Larry.Finger@lwfinger.net>
Tested-by: Markus Kanet <dvmailing@gmx.eu>
Cc: Markus Kanet <dvmailing@gmx.eu>
Signed-off-by: John W. Linville <linville@tuxdriver.com>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 238ab78469 upstream.
If blk_init_queue fails, we do not call put_disk on the current dr
(dr is decremented first in the error handling loop).
Reviewed-by: Ben Hutchings <ben@decadent.org.uk>
Signed-off-by: Herton Ronaldo Krzesinski <herton.krzesinski@canonical.com>
Signed-off-by: Jiri Kosina <jkosina@suse.cz>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 02b898f2f0 upstream.
setup_conf in raid1.c uses conf->raid_disks before assigning
a value. It is used when including 'Replacement' devices.
The consequence is that assembling an array which contains a
replacement will misbehave and either not include the replacement, or
not include the device being replaced.
Though this doesn't lead directly to data corruption, it could lead to
reduced data safety.
So use mddev->raid_disks, which is initialised, instead.
Bug was introduced by commit c19d57980b
md/raid1: recognise replacements when assembling arrays.
in 3.3, so fix is suitable for 3.3.y thru 3.6.y.
Signed-off-by: NeilBrown <neilb@suse.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit ad2fab36d7 upstream.
gpios requested with invalid numbers, or gpios requested from userspace via sysfs
should not try to be deferred on failure.
Signed-off-by: Mathias Nyman <mathias.nyman@linux.intel.com>
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit d79550a7bc upstream.
->last_ier is an unsigned long but the high bits can't be used int the
original code because the shift wraps.
Signed-off-by: Dan Carpenter <dan.carpenter@oracle.com>
Signed-off-by: Linus Walleij <linus.walleij@linaro.org>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
commit 9756fe38d1 upstream.
This box claims to have an LVDS interface but doesn't
actually have one.
Signed-off-by: Sjoerd Simons <sjoerd.simons@collabora.co.uk>
Signed-off-by: Daniel Vetter <daniel.vetter@ffwll.ch>
Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
{kind=link}